[CS294 - 112 정리] Lecture12 - Advanced Model Learning and Images
in Reinforcement learning / Reinforcement learning on Cs294
Table of Contents
Overview
- Managing overfitting in model-based RL
- What’s the problem?
- How do we represent uncertainty?
- Model-based RL with images
- The POMDP model for model-based RL
- Learning encodings
- Learning dynamics-aware encoding
- Goals:
- Understand the issue with overfitting and uncertainty in model-based RL
- Understand how the POMDP model fits with model-based RL
- Understand recent research on model-based RL with complex observations
Problem: Overfitting
A performance gap in model-based RL
- Pure model-based는 작은 step(10분)에서도 학습이 진행되지만, overfitting 으로 충분히 학습할수 있는 기회를 놓치게 된다(DNN은 big capacity를 가짐).
- Overfitting을 줄이기 위해 smaller model(=dynamics), regularization을 이용하기도 한다.
- 그러나, 작은 모델을 선택하면 underfit 문제발생.
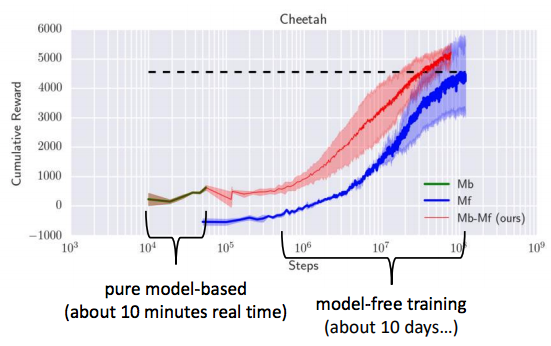
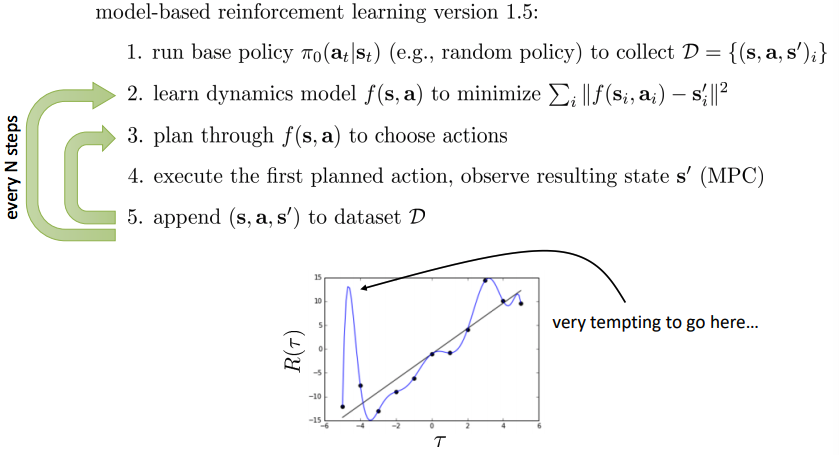
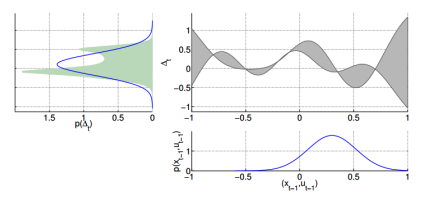
- Overfitting은 아래의 그림과 같고, model-based RL 1.5 버전에서 3번째 경우 action을 선택함(_adversary exploit, model이 optimistic하여 mistake)에 있어 overfitting으로 인한 exploitation으로 좋은 성능을 얻지 못하게 되어 적당한 exploration을 필요 로 한다.
- 아래 사진에서 보게되면 왼쪽 실제 reward는 작지만 오버피팅되어 reward이 큰 줄 알고 그쪽으로 갈려고 하게 됨.
Solution
- Idea(Remember from last time…)
- Gaussian Process(GP, Bayesian model) 를 이용하여 dynamics를 구성함으로써 uncertainty(Gaussian distribution에서 next state에 포함되어짐)를 다룰수 있게 되었다.
- Version 2.0 RL 알고리즘
- Gaussian Process(GP, Bayesian model) 를 이용하여 dynamics를 구성함으로써 uncertainty(Gaussian distribution에서 next state에 포함되어짐)를 다룰수 있게 되었다.

- 이전에는 action을 선택하기 위해서는 dynamics를 이용하여 planning.
- GP 모델을 사용하여 진행, policy를 최적화(action 선택)하기 위해 dynamics를 backpropagation.
- 방법은 moment matching 을 이용하여 non-Gaussian을 Gaussian으로 projection 시킨다.

Why are GPs so popular for model-based RL?
- GPs는 uncertainty 추정을 잘한다
- 데이터가 주어진 곳(빨간점)이 아닌 지점은 불확실하다는 것을 보임
- 목표: 멋진 바다 절경을 보는 것(절벽에 가까워짐), 떨어지면 안됨
- 작은 빨간 타원: 불확실성 고려 X
- 가까이 접근
- 큰 빨간 타원: 불확실성 고려
- 절벽으로 접근하지 않음
- 비록 평균이 같더라도 high-variance 하에서는 expected reward는 매우 작다.
- 예를 들어, 절벽위에서 풍경을 보는 것이 가장 멋지지만 위험성이 크다.
- 작은 빨간 타원: 불확실성 고려 X
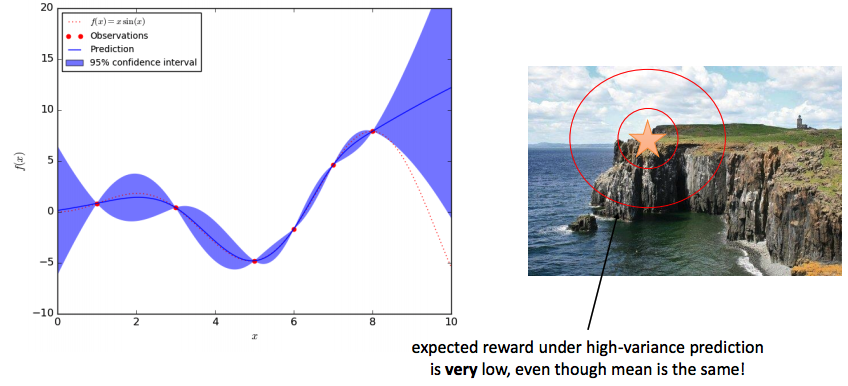
Intuition behind uncertainty-aware RL
- Uncertainty dynamics 을 도입하면 mean에 대한 단순히 high reward를 가지는게 아닌 expectation(dynamics에 대한 uncertainty)에서의 high reward를 얻기 위한 action만을 취함
- Model: High variance, (“exploiting”)이 아니라 “exploration”도 실행되게 된다
- 점점 model이 조정되며 좋아질 것(confidence가 높아진다)
There are a few caveats…
- 더 좋은 모델을 가지기 위해서 exploration이 필요
- 간단히 말해서, High uncertainty라고 region을 가지 않는 것을 추천하지 않음(High uncertainty region으로 exploration 필요)
- Idea: expected reward 를 취하면, catastrophe인 new region을 피할 수 있다.
- Expected value는 pessimistic, optimistic value와 동일하지 않다.
- Expected value이 크다고 낙관적인 값이 아니고, 반대도 마찬가지로 비관적인 값을 의미하지 않는다.
- Expected value는 pessimistic, optimistic value와 동일하지 않다.
- …하지만 expected value는 종종 좋은 시작점이다
Uncertainty modeling
How can we have uncertainty-aware models(Uncertainty modeling 방법)?
- Idea1: output을 entropy 사용
- 첫 번째는 discrete(softmax), 두 번째는 continous(Gaussian)
- 이 방법은 왜 충분하지 않을까?
- Variance가 생기는 이유는 단일하지 않다.
- Overfitting으로 생길 수도 있으나, nature noise로 인해 발생
- Data에 대해 model은 확신하지만, 우리는 model에 대해 확신이 없다
- Variance가 생기는 이유는 단일하지 않다.
- \(1\). Epistemic(지식의) or model uncertainty
- \(2\). Aleatoric(우연) or statistical uncertainty
- Idea2: Model uncertainty를 추정
- Data를 이용하여 uncertainty modeling이 아닌, 파라미터를 이용하여 model에 대한 uncertainty 추정
- 일반적으로, 아래를 추정한다.
- 데이터 셋과 파라미터간의 엔트로피가 동일한 관계
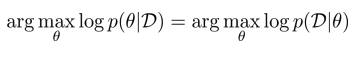
- 대신 \(p(θ \mid D)\)를 추정할 수 있지 않을까?
- \(p(θ \mid D)\) 엔트로피는 model uncertainty를 의미
- 아래와 같은 수식으로 prediction:
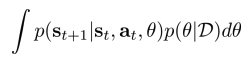
Quick overview of Bayesian neural networks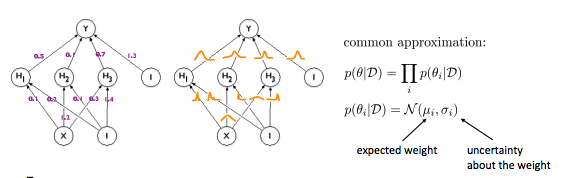
Bootstrap ensembles
- 여러 모델들을 학습하고 동의할지 살펴보는 방법
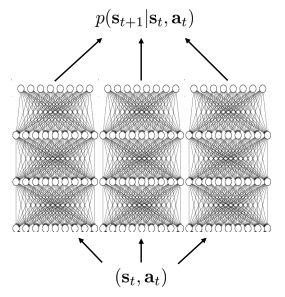
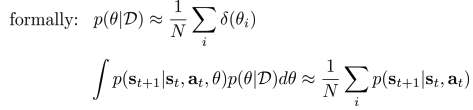
- 학습방법:
- Main idea: “independent” model를 얻기 위해 “independent” dataset을 생성해야한다
- D에서 샘플링된 \(D_i\)에서 \(\theta_i\)를 학습
Bootstrap ensembles in deep learning
- 기본적으로 동작
- 모델의 수가 일반적으로 작기때문에(< 10), 매우 대충 approximation된다.
- 재복원 표본추출(Resampling with replacement)은 불필요 하다.
- SGD 및 random initialization은 일반적으로 모델을 충분하게 독립적으로 만듬.
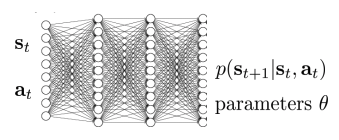
How to plan with uncertainty
Uncertainty를 가지고 planning 하는 법(model-based RL)
- 이전:
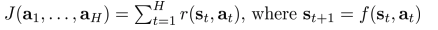
- 현재 \(f_i\): deterministic model에 대해서 distribution
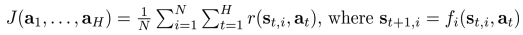
- 일반적으로, candidate action sequence \(a_1,…,a_H\):

Model-based methods with images
Recap: Model-based RL
- Dataset을 수집하기 위해 base policy 실행
- 반복:
- Dynamics model loss정의하여 dynamics model 학습
- Action 선택하기 위해 dynamics를 통해 planning
- Action을 실행하여 결과 data를 dataset에 추가
- 반복:

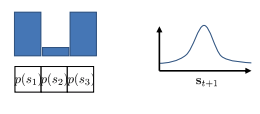
What about POMDPs?
- Observation가 주어지고 policy를 통해 action 선택

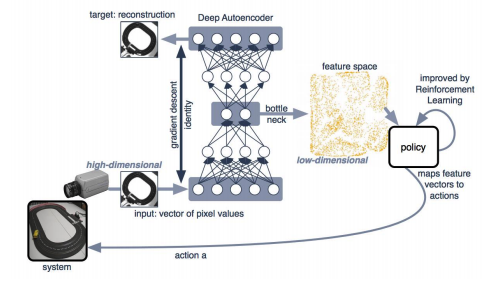
Learning in Latent Space
- Key idea: Embedding \(g(o_t)\) 학습하고, latent space에서 학습

Case: model-free
- Eploratory policy로 data 수집
- Image의 low-dimensional embedding 학습
- Feature vector(state로 사용)를 action으로 mapping(= policy 학습)
- RL을 사용하여 improvement.
- Embedding으로 function approximation으로 q-learning 실행
Embedding: low-dimensional and summarizeds the image
- Pros:
- 매우 효율적으로 visual skill을 학습
- Cons:
- Autoencoder는 알맞은 representation을 회복시키지 못할 수 있다.
- Model-based 방법에는 적합하지 않다.

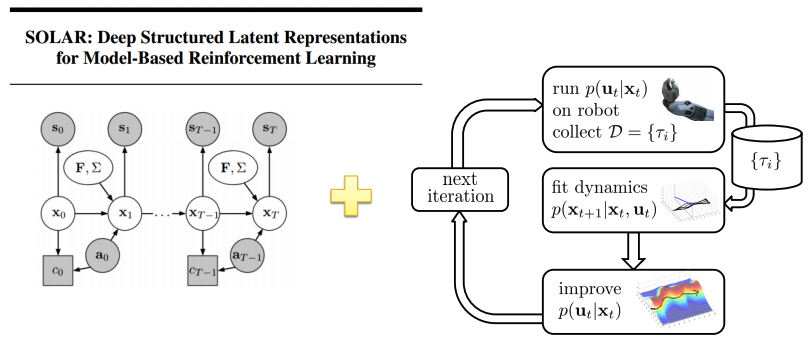
Case: model-based
- Exploratory policy로 data 수집
- Image의 smooth, structured embedding 학습
- Embedding으로 local linear model 학습
- Goal image에 도달하는 학습을 위해 local model으로 iLQR 실행.


- State들을 사용하지 않기 때문에, reward를 필요로 한다.

Case: model-based
- Data 수집
- (Jointly) image & dynamical model의 embedding학습
- Embedding은 modeling 되어진다.
- Image의 목표 도달하는 학습을 위해 iLQR 실행

Embedding that can be modeled
Local models with images
Learn directly in observation space
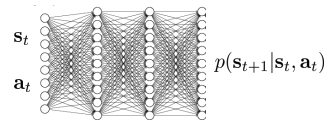
- Embedding을 통해 학습을 하지 않고 observation(e.g., image)으로 바로 \(p(o_{t+1} \mid o_t, a_t)\) 학습.
- CNN, LSTM을 이용하여 학습.
- Task 완벽하게하기 위해 prediction사용.
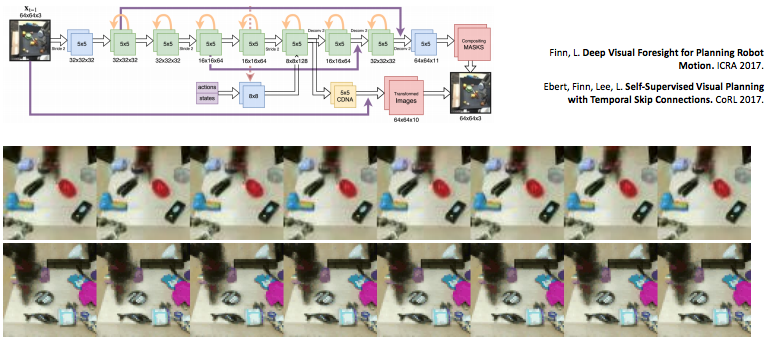

Predict alternative quantities
- Action의 집합을 택한다면:

- Pros:
- Task와 관련된 quantities만은 prediction
- Conds:
- Manual하게 quantities를 picking 해야하고, 직접 observation을 할 수 있어야만 한다.