[PAPER-Review] End-to-End Training of Deep Visuomotor Policies, Sergey, Finn, 2016
in Reinforcement learning / Reinforcement learning on Mbrl
Table of Contents
- [End-to-End Training of Deep Visuomotor Policies, Sergey, Finn, 2016]
- [Deep Spatial Autoencoders for Visuomotor Learning, Finn, 2016]
- [Deep Visual Foresight for Planning Robot Motion, Finn, Sergey, 2017]
[End-to-End Training of Deep Visuomotor Policies, Sergey, Finn, 2016]
Abstract
- Policy search 방법은 task의 넓은 범위에 대해 control policy들을 학습할 수 있도록하지만, policy search의 실질적인 응용은 인지(perception) 및 state estimate, low-level control에 대한 hand-engineered components들을 종종 요구.
- 이 논문에서는 다음의 질문들에 대한 대답이 목표
- Perrception, control 시스템을함께(jointly) end-to-end를 학습하는 것을 각 성분(component)을 별개로 학습하는 것보다 좋은 성능을 제공?
- 저자는 raw image observation을 직접 로봇 모터의 토크를 매핑하는 policy들을 학습 하기 위해 사용되는 방법을 develop.
- Policy들은 92,000개 파라미터를 가지는 deep convolutional neural networks(CNNs)에 의해 representation되며, simple trajectory-centric RL 방법에서 제공된 supervision을 가지고 policy search를 supervised learning으로 transformation하는 guided policy search 방법을 사용하여 학습.
- 뚜껑을 물병에 부착하는 것와 같은 vision 및 control간의 close coordination을 요구하는 실제 환경 manipulation task의 range를 저자의 방법으로 평가하고 이전 policy search 방법의 range와 현재 simulated와 비교
Keywords: RL, Optimal Control, Vision, NN
[Deep Spatial Autoencoders for Visuomotor Learning, Finn, 2016]
Abstract
- RL은 robotic motion skill들의 자동적으로 획득하기 위한 powerful, flexible framework을 제공.
- 그러나, RL을 적용하는 것은 task-relevant objects의 configuration을 포함한 state의 detailed representation의 충분한 양을 요구.
- 저자는 카메라 이미지로부터 state representation을 직접 학습하여 state-space construction을 자동화하는 접근법을 제안
- 저자의 방법은 object들의 위치와 같은, 현재 task에 대한 environment를 묘사(describe)하는 feature point들의 집합을 얻기위해 deep spatial autoencoder 를 사용.
- 최종 controller는 closed-loop control을 가지고 world의 object들을 동적으로 조작하도록(dynamically manipulate) 로봇이 이용되며 학습된 feature point들에 대해 지속적으로 반응.
- 다양한 위치에서 hook에서 rope를 loop를 hanging하고 spatula를 사용하여 rice의 bag을 들어올리거나 자유롭게 쌓여있는 block을 pushing하는 task들에 대해 PR2 로봇에 적용한 것을 시연.
- 각각의 task에서, 저자의 방법은 자동적으로 task-relevant objects를 track하는 것을 학습하고 robot’s arm을 가지고 configuration을 manupulate

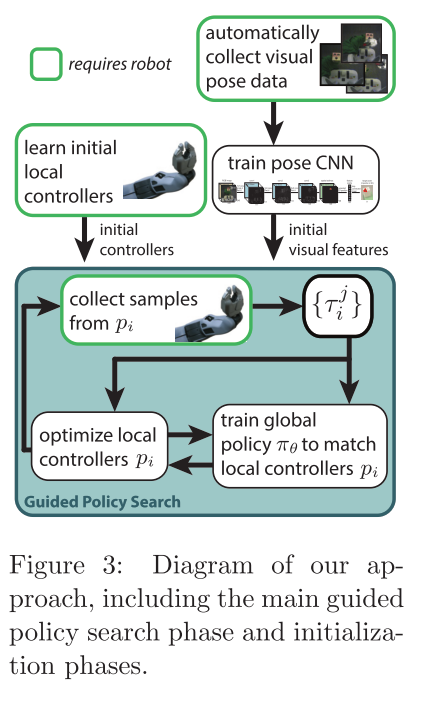
[Deep Visual Foresight for Planning Robot Motion, Finn, Sergey, 2017]
Abstract
- 많은 skill 및 환경들에 대한 robot learning을 확대(scaling up)하는데 가장 중요한 것(key challenge)은 human supervision에 대한 요구를 제거하면, 로봇은 own data를 수집할 수 있고 human feedback의 비용에 대한 제한이 되는 것 없이 own performance를 향상시킬 수 있다.
- MBRL은 detailed human supervision없이 task 및 environment의 넓은 range에 대해 flexible predictive model을 제공할 수 있는 action의 effect들을 예측하는 방법을 agent가 학습할 수 있다고 약속(promise)
- 저자는 labelled training data을 완전히 사용할 수 있는 model-predictive control을 가지고 deep action-conditioned video predition model을 개발