[CS294 - 112 정리] Lecture2 - Supervised Learning and Imitation
in Reinforcement learning / Reinforcement learning on Mbrl
Table of Contents
- Today’s Lecture
- Terminology & notation
- Imitation Learning
- DAgger 문제점
- Case study
- Imitation Learning의 한계
- Reference
Today’s Lecture
- 순차적 의사결정 문제(sequential decision problem) 정의
- Imitation learning: 의사결정을 위한 supervised learning.
- 직접 모방하는 작업?
- 더욱 잘, 자주 동작하는 방법?
- (Deep) imitation learning에서 최근 연구의 case studies.
- Imitation learning에서 빠진 부분?
- Reward 함수가 다음주부터 다뤄지는 이유
- 목표:
- 정의 및 표기법 이해.
- 기초적인 imitation learning 알고리즘 이해.
- 강점 및 약점 이해.
Terminology & notation
- 일반적인 지도학습(supervised learning) 은 다음과 같다:
- 입력: image
- 출력: category
- 중간: 학습하고자 하는 model, probability distribution(확률 분포)을 파라미터화하는 것 - conditional probability distribution(조건부확률분포).
- 입력: image(observation)
- 출력: categorical variable(label)
- Theta: parameterized distribution의 파라미터
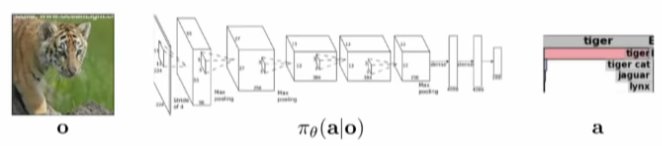
순차적 의사결정(Sequential decision making)문제 로 변경하기 위해 decision, sequential things를 추가
- Sequential 부분: t, time step
decision 부분: a, 출력을 action으로 변경.
- \(\pi\)가 discrete할 수도 있고, continous할 수도 있음.
- Discrete: real-value number
- Continous: Gaussian distribution(mean, variance)
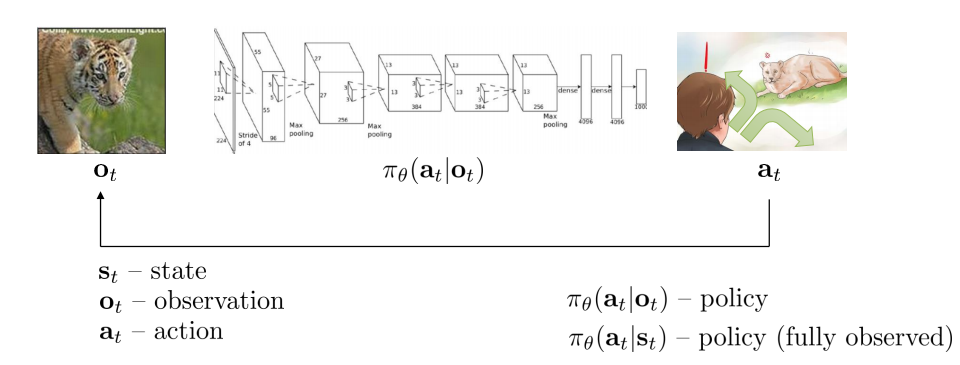
- Notation
- observation: \(\sigma_t\)
- action: \(a_t\)
- policy: \(\pi_\theta (a_t \bar o_t)\), conditional distribution
- 일반적으로는 parially observed하기에 \(o_t\)로 주어진다
- 만약 fully observed, \(o_t\)를 \(s_t\)로 대체.
- state: \(s_t\)
- State와 observation의 관계
- Observation: state의 lossy consequence(손실된 결과)
- State: 특성을 간단히 요약한 것이며 미래를 예측하는데 sufficient kind.
Fully obserbability: 컴퓨터는 입력을 pixel의 값으로만 구성, 물리적 특성을 가진 모멘텀 및 치타와 가젤의 위치를 알 수는 없다 - hidden

Partial obserbability : 치타가 차에 가려져 있다. state는 추론할 수 없더라도 위 상황과 동일(치타, 가젤의 물리적 특성은 존재하기 때문).

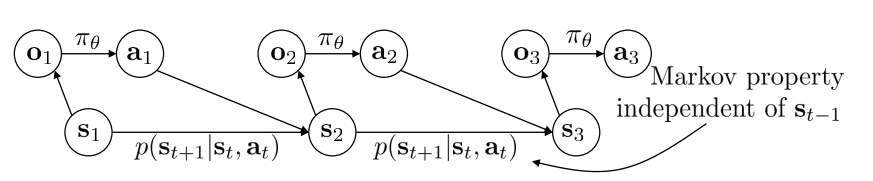
- 이러한 관계를 graph(모델, dynamic Bayesian network)로 그리면 다음과 같다:
- 각 시간에 따라 분리
- policy(\(\pi _ \theta\)) : o에서 a로 매핑, conditional probability distribution.
- p(\(s_{t+1} \bar s_t, a_t\)) : transition function, 현재의 state, action이 다음 state에 어떻게 영향을 끼치는 지 나타냄.
- observation: state로부터 생성됨
- State \(s_3\)는 \(s_1\)과는 독립적.
- 즉, 현재의 state만 있다면 추가적인(과거) 정보는 필요가 없다.
- 각 시간에 따라 분리
Imitation Learning
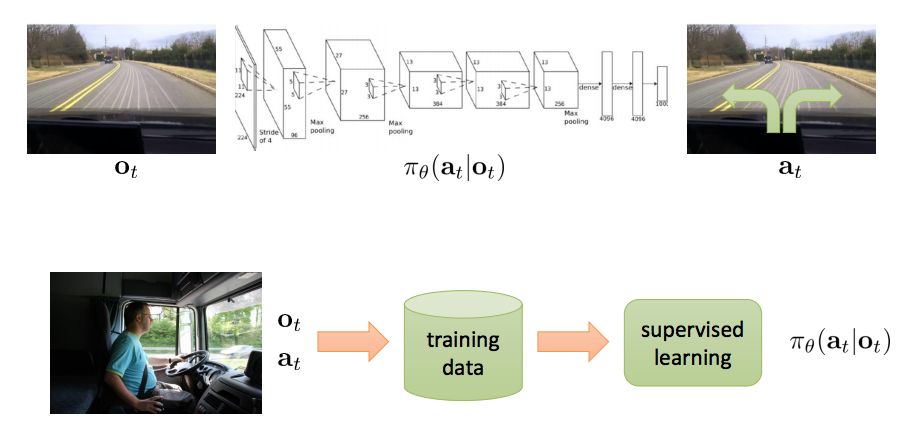
- Behavior cloning
- 드라이버가 운전을 하며, 카메라 녹화 및 steering wheel을 encoding = data set.
- 이를 이용하여 supervised learning 을 통해 training(stochastic gradient descent 이용)하여 policy 도출.
- 잘 동작? 일반적으로 No!!!!!!
- 주어진 data set을 이용하여 진행하게 되면, 초반에는 잘 동작하지만 작은 차이가 발생해도 점점 차이가 커지며 발산하게 된다.
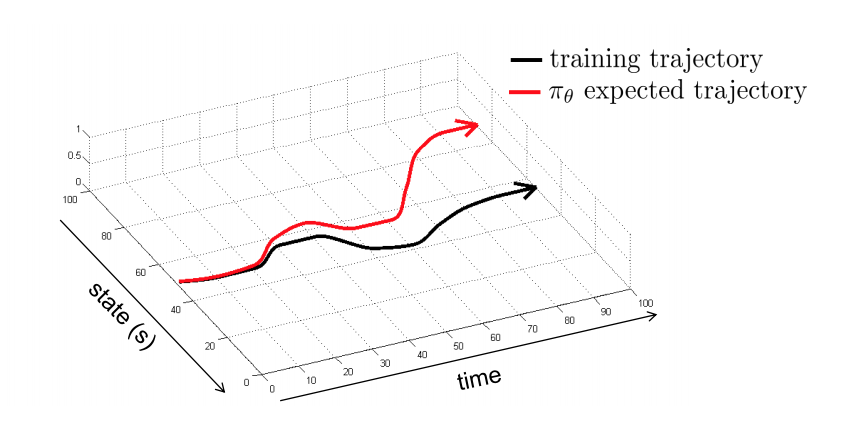
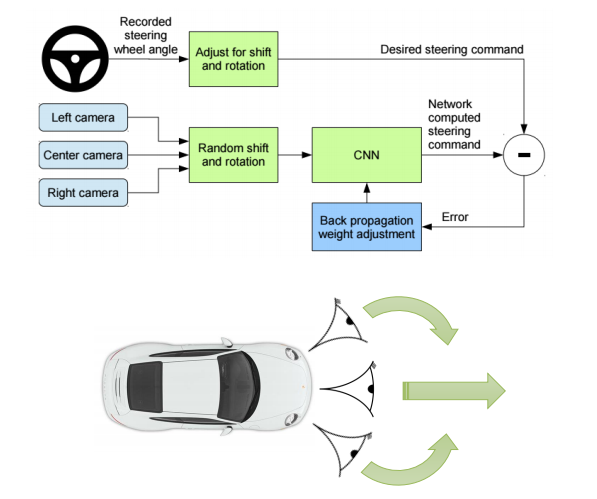
- 잘 동작하기 위해서 차량 앞에 추가적인 카메라를 설치하여 안정성 확보(수렴).
- 각 카메라에서 결정되는 action을 서로 보상하여 steering - policy를 stabilize.
- 노이즈를 추가(각 카메라)하고 이를 서로 보완하여 distribution 생성.
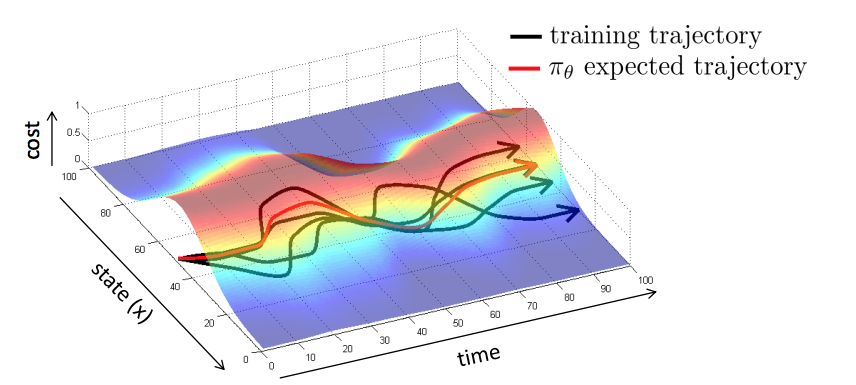
- 학습을 stabilizing controller(LQR)으로 모방 학습
- 더욱 잘 동작하게 만드는 방법:
- 문제점: 아래 사진과 같은 방법으로 모방 학습을 진행
- \(p_{data}\): 사람의 data set
- \(p_{\pi_\theta}\): 주어진 데이터와 차이가 발생.
- 문제점: 아래 사진과 같은 방법으로 모방 학습을 진행
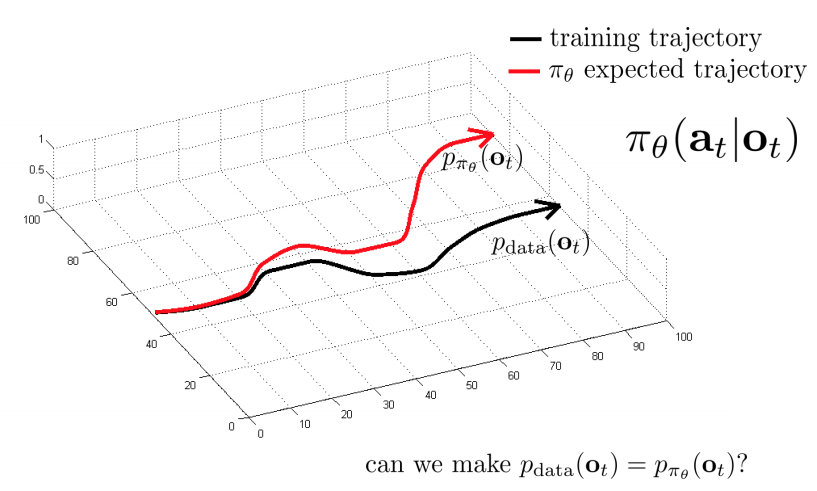
- 해결책: \(p_{data} = p_{\pi_\theta}\) 만들 수 있을까?
- DAgger: Dataset Aggregation
- 목표: \(p_{data}\) 대신에 \(p_{\pi_\theta}\)에서 training data를 수집
- 방법: \(\pi_\theta\)실행, 그러나 label \(a_t\)가 필요.
- 사람의 데이터 \(D={o_1,a_1, …, o_N, a_N}\)을 모아서(사람이 직접 운전을 해서) \(\pi_\theta (a_t \bar o_t)\)를 학습.
- \(\pi_\theta(a_t \bar o_t)\)를 기반으로 실행하고, \(D_\pi = {o_1, …, o_M}\) 을 얻는다.
- 사람이 직접 \(D_\pi\)에 대해 action label을 달아준다(외부개입).
- \(D \leftarrow D \cup D_\pi\) , 원래의 데이터셋과 합쳐준다(aggregate).
- 1~4를 반복한다.
- DAgger: Dataset Aggregation

문제점 : 사람의 노동력(a lot of effort, right action)이 너무 많이 들어간다.
DAgger 문제점
많은 데이터(외부개입)없이 성능향상 할 수 있는 방법은 무엇인가?
- DAgger는 distributional “drift”의 문제 를 다뤘다.
- 만약 우리의 모델이 좋다면, ”drift”가 발생하지 않을까?
- 전문가의 행동을 매우 정확하게 정확하게 모방해야 하지만, overfit은 안된다(generalization이 필요)
왜 전문가와 매칭하는 것이 실패할까?
\(1\). Non-Markovian behavior
- 같은 경우라도, 이전에 무슨 일이 일어났는지 관계없이 똑같은 행동을 두번 할까?
- 인간의 시연들이 종종 부자연스럽다.
- (Markov property를 이용한다면 과거의 상태에 독립적으로 현재상태에서 최적의 선택을 해야하는데, 사람은 그렇지 못하다) 과거의 state, 경험이 현재의 선택에 영향을 끼친다.
- 해결방법: 전체 history를 사용하는 방법(RNN, LSTM)
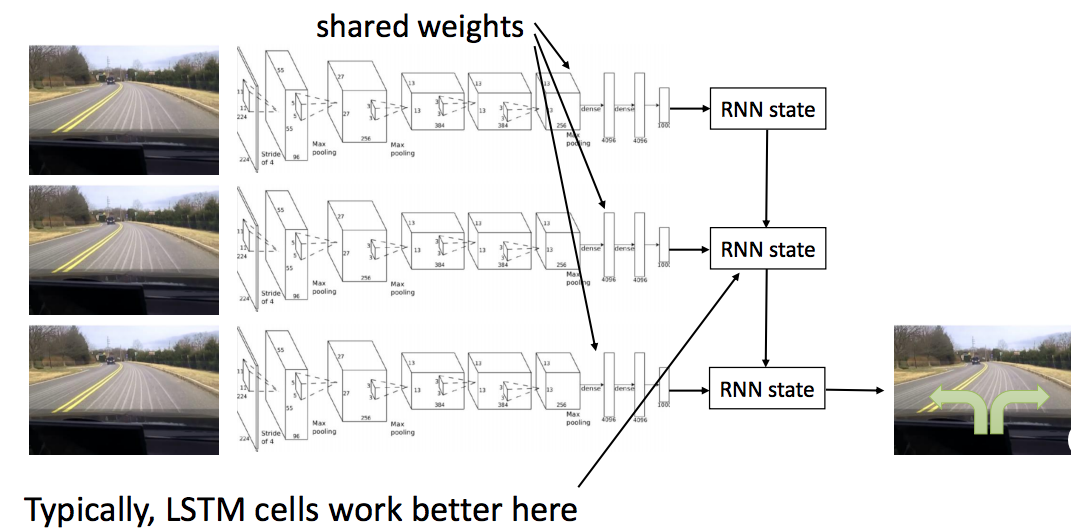
\(2\). Multimodel behavior
- 같은 state가 주어지더라도 다양한 행동이 존재할 수 있다.
- (사람은 가끔 왼손으로 운전했다가, 오른손으로 운전했다가, 슬펐다가 기뻤다가 등등 데이터에 영향을 주는 많은 (예측할 수 없는) 요인을 갖고 있다. 따라서 같은 상황에서도 다른 선택을 한다.)

- 해결책:
Output Mixture of Gaussians : 최종 행동을 뽑을때 하나의 Gaussian에서 뽑는 것이 아니라 여러개의 Gaussian을 합쳐서 뽑는다. 단순한 방법이다.
- Latent variable model : 일반적으로 사용되긴 하지만 다소 복잡하다. Output은 하나의 Gaussian을 내뱉도록 그대로 두고, 중간에 random noise를 더하여 학습 시킨다.
- Conditional variational autoencoder
- Normalizing flow/realNVP
- Conditional variational autoencoder
Stein variational gradient descent
- Autoregressive discretization : setup이 약간 지저분하지만 Latent variable model보다는 단순하다. softmax를 통해 이산화된 확률분포 를 뽑아낸다. 이 확률분포를 통해 샘플링을 한다. 또다른 네트워크에 입력으로 넣어주고 다시한번 확률분포를 뽑아낸다. (첫번째 뽑아준 값을 condition으로 하여 두번째 값을 뽑아내는 셈이다.) 이 과정을 n번 반복하여 n dimension의 출력을 뽑아내게 된다.
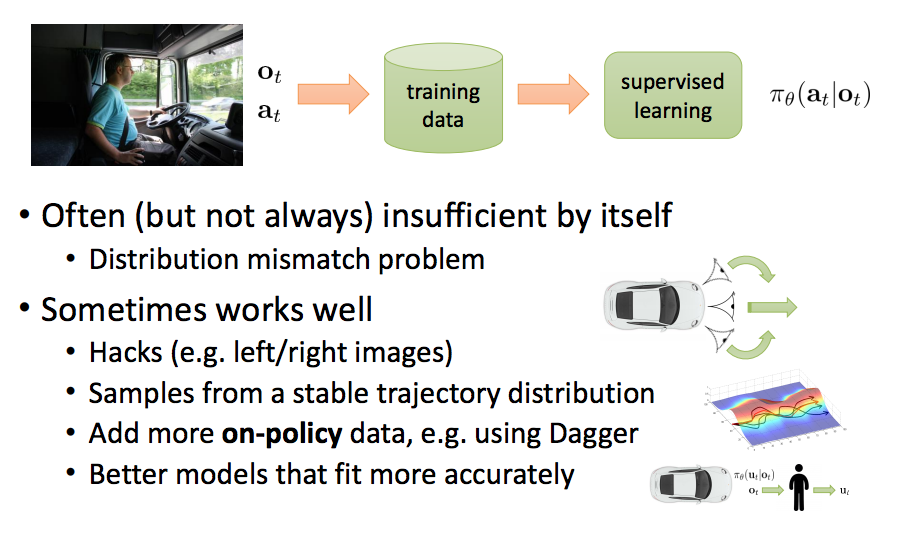
## Imitation learning: recap
- 종종(항상은 아니고) 이 방법만으로는 불충분.
- 문제: 분포 불일치.
- 다음과 같은 방법을 사용하여 잘 동작하게 할 수 있다.
- Hacks (e.g. left/right images) - 꼼수를 사용한다
- State trajectory 분포로부터 sampling
- 더 많은 On-policy 데이터를 추가(e.g. Dagger 사용)
- 더욱 정확하게 모델링
Case study
- Trail following as classification
- A Machine Learning Approach to Visual Perception of Forest Trails for Mobile Robots, Giusti et al., ‘16 논문에서는 Quadrotor을 모방 학습을 통해 숲속길을 따라 주행할 수 있게 하였다.
- input으로는 Monocular RGB 카메라만을 사용하면서도 Distributional drift문제를 개선하였다. 이를 CNN을 통해 처리하였고, output은 왼쪽, 오른쪽, 앞 세가지의 label을 사용하였다.
- 해결 포인트는 End to End Learning for Self-Driving Cars에서 언급한것중 하나대로 카메라를 왼쪽, 앞, 오른쪽 세개를 사용하는 것이다. 사람이 머리에 카메라를 달고 숲속을 걸어다니며 약 20k 장의 학습데이터를 모았다.

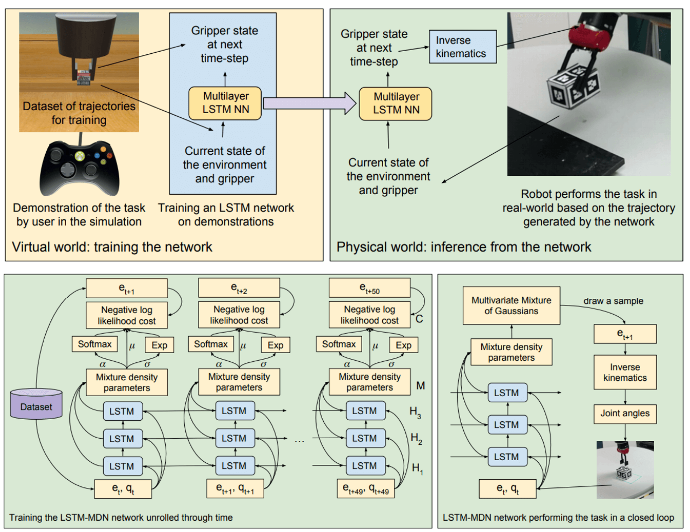
- Imitation with LSTMs
- From virtual demonstration to real-world manipulation using LSTM and MDN, Rahmatizadeh et al., ‘16 논문에서는 박스 옮기는 로봇을 학습시키는 연구를 소개한다. 가상세계에서 로봇을 학습시킨 후 현실세계에서 테스트한다.
- Non-Markovian behavior를 LSTM으로 다루었다. 또한 Mixture Density Network(MDN)을 사용하여 Multimodal behavior문제 또한 개선하였다.
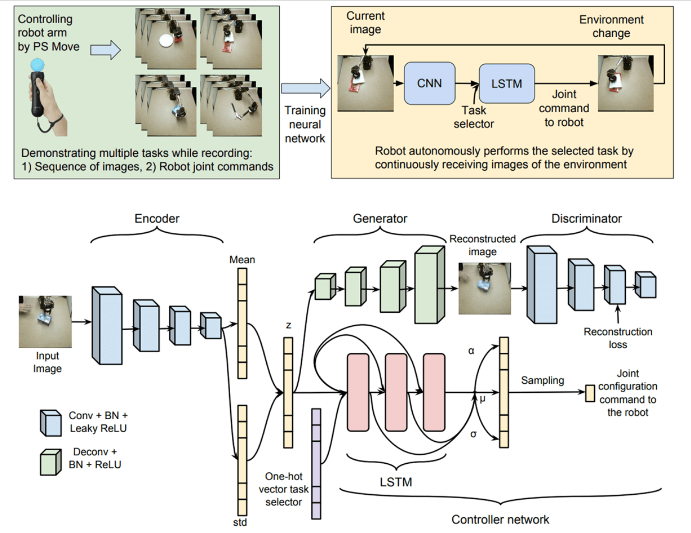
- Multi-Task manipulation with inexpensive robots
- Vision-Based Multi-Task Manipulation for Inexpensive Robots Using End-To-End Learning from Demonstration, Rahmatizadeh et al., ‘17 논문은 바로 위에 언급한 논문의 저자와 본 강의의 교수가 함께 작성한 논문이다.
- 일단 제목에서도 나타내듯이 비교적 저렴한 비용으로 장비 셋팅을 하였다. 집게가 달린 6-axis Lynxmotion AL5D robot을 사용하였고, 로봇팔에 카메라를 달아 input으로 사용하였다.
- Leap motion, Playstation controller까지 합쳐서 총 500달러가 들었다고 한다. 코드까지 공개하며 독자들에게 실험셋팅을 해볼 것을 권유하고 있다. 이러한 셋팅을 이용하여 사람이 로봇을 컨트롤 한 것을 학습하였다. 시도한 테스크는 물건을 집고 옮기고, 밀고, 닦고 등 다섯가지이다. 윗 논문과 마찬가지로 LSTM을 사용하였고, One-hot vector을 함께 넣어줌으로써 multi task를 제어하였다. 또한 VAE-GAN구조를 결합하여 좀더 안정적인 학습을 한다.
- Other topics in imitation learning
- Structured prediction:
- 번역 task에서, where are you?라는 질문에 I’m in work라는 대답은 적절치 않다. 따라서 work를 지우고 I’m in school로 바꾸어준다. 요점은, output간의 관계를 고려해서 의사결정에 도움을 준다는 것이다. DAgger을 이용해 더 적절한 답안을 찾아내도록 보완가능하다.
- Inverse reinforcement learning
- 행동을 모방하는 대신, 목표가 무엇인지 추론한다. (나중에 다시 다룬다.)
- Structured prediction:
Imitation Learning의 한계
- 사람이 데이터를 가공해야하는데, 보통은 한계가 있다.
- 그러나 딥러닝은 데이터가 많아야 잘 작동한다.
- 어떤 테스크는 사람조차 제대로 못한다. (하늘을 날아다니거나, 모터를 제어하는 등)
- 사람은 알아서 학습하는데 기계는 그러기 힘들다.
- 스스로의 경험에 의한 무제한적인 데이터가 필요하다.
- 연속적으로 스스로 학습해야한다.